2013年上半年软考《软件设计师》下午模拟试卷二
-
阅读以下函数说明、图和C程序代码,将C程序段中(1)~(6)空缺处的语句填写完整。
[说明]
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如,设散列函数为Hash(Key)=Key mod7,记录的关键字序列为15,14,21,87,96,293,35,24, 149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图2-27所示。
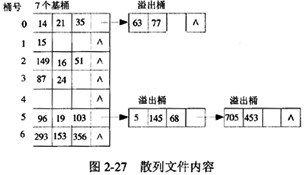
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是:若新元素NewElemKey正确插入散列文件中,则返回值0;否则返回值-1。
采用的散列函数为Hash(NewElemKey)=NewElemKey%P,其中P设定基桶的数目。
函数中使用的预定义符号如下。

-
阅读以下技术说明及C++代码,将C++程序中(1)~(5)空缺处的语句填写完整。
[说明]
在一公文处理系统中,开发者定义了一个公文类OfficeDoc,其中定义了公文具有的属性和处理公文的相应方法。当公文件中内容或状态发生变化时,关注此OfficeDoc类对象的相应的DocExplorer对象都要更新其自身的状态。一个OfficeDoc对象能够关联一组DocExplorer对象。当OfficeDoc对象的内容或状态发生变化时,所有与之相关联的DocExplorer对象都将得到通知,这种应用被称为Observer(观察者)模式。以下代码采用C++语言实现,能够正确编译通过。
[C++代码]

-
阅读以下技术说明及Java代码,将Java程序中(1)~(5)空缺处的语句填写完整。
[说明]
在一公文处理系统中,开发者定义了一个公文类OfficeDoc,其中定义了公文具有的属性和处理公文的相应方法。当公文件的内容或状态发生变化时,关注此OfficeDoc类对象的相应的DocExplorer对象都要更新其自身的状态。一个OfficeDoc对象能够关联一组DocExplorer对象。当OfficeDoc对象的内容或状态发生变化时,所有与之相关联的DocExplorer对象都将得到通知,这种应用被称为Observer(观察者)模式。以下代码采用Java语言实现,能够正确编译通过。
[Java代码]

-
假设有6个作业job1,job2,…,job6;
完成作业的收益数组p=(p[1],p[2],p[3],p[4],p[5],p[6])=(90,80,50,30,20,10);
每个作业的处理期限数组d=(d[1],d[2],d[3],d[4],d[5],d[6])=(1,2,1,3,4,3)。
请应用试题中描述的贪心策略算法,给出在期限之内处理的作业编号序列(4) (按作业处理的顺序给出),得到的总收益为(5)。
-
对于本试题的作业处理问题,用图3-25的贪心算法能否求得最高收益? (6)。(能或不能)
用贪心算法求解任意给定问题时,是否一定能得到最优解? (7)。(能或不能)
-
简要解释图3-22中用例U1和U3之间的extend关系的内涵。
-
阅读下列算法说明和流程图,根据要求回答问题1~问题3。
[说明]
某机器上需要处理n个作业job1,job2,…,jobn,其中:
(1)每个作业jobi(1≤i≤n)的编号为i,jobi有一个收益值P[i]和最后期限值d[i];
(2)机器在一个时刻只能处理一个作业,而且每个作业需要一个单位时间进行处理,一旦作业开始就不可中断,每个作业的最后期限值为单位时间的正整数倍;
(3)job1~jobn的收益值呈非递增顺序排列,即p[1]≥p[2]≥…≥p[n];
(4)如果作业jobi在其期限之内完成,则获得收益p[i];如果在其期限之后完成,则没有收益。
为获得较高的收益,采用贪心策略求解在期限之内完成的作业序列。图3-25是基于贪心策略求解该问题的流程图。
(1)整型数组J[]有n个存储单元,变量k表示在期限之内完成的作业数,J[1..k]存储所有能够在期限内完成的作业编号,数组J[1..k)里的作业按其最后期限非递减排序,即d[J[1]]≤…≤d[J[k]]。
(2)为了便于在数组J中加入作业,增加一个虚拟作业job0,并令d[0]=0,J[0]=0。
(3)算法大致思想是:先将作业job1的编号1放入J[1],然后,依次对每个作业jobi(2≤i≤n)进行判定,看其能否插入到数组J中。若能,则将其编号插入到数组J的适当位置,并保证J中作业按其最后期限非递减排列;否则不插入。
jobi能插入数组J的充要条件是:jobi和数组J中已有作业均能在其期限之内完成。
(4)流程图中的主要变量说明如下。
i:循环控制变量,表示作业的编号;
k:表示在期限内完成的作业数;
r:若jobi能插入数组J,则其在数组J中的位置为r+1;
q:循环控制变量,用于移动数组J中的元素。

请将图3-25中的(1)~(3)空缺处的内容填写完整。
-
根据说明中的描述,使用表3-11给出的类的名称,给出图3-23中的A~D所对应的类。
-
阅读以下技术说明,根据要求回答问题1~问题4。
[说明]
某汽车停车场欲建立一个信息系统,已经调查到的需求如下。
1.在停车场的入口和出口分别安装一个自动栏杆、一台停车卡打印机、一台读卡器和一个车辆通过传感器等,其示意图见如图3-21所示。

2.当汽车到达入口时,驾驶员按下停车卡打印机的按钮获取停车卡。当驾驶员拿走停车卡后,系统命令栏杆自动抬起;汽车通过入口后,入口处的传感器通知系统发出命令,栏杆自动放下。
3.在停车场内分布着若干个付款机器。驾驶员将在入口处获取的停车卡插入付款机器,并缴纳停车费。付清停车费之后,将获得一张出场卡,用于离开停车场。
4.当汽车到达出口时,驾驶员将出场卡插入出口处的读卡器。如果这张卡是有效的,系统命令栏杆自动抬起;汽车通过出口后,出口传感器通知系统发出命令,栏杆自动放下。若这张卡是无效的,系统不发出栏杆抬起命令而发出告警信号。
5.系统自动记录停车场内空闲的停车位的数量。若停车场当前没有车位,系统将在入口处显示“车位已满”信息。这时,停车卡打印机将不再出卡,只允许场内汽车出场。
根据上述描述,采用面向对象方法对其进行分析与设计,得到如表3-11所示的类/用例/状态列表,如图3-22所示的用例图,如图3-23所示的初始类图以及如图3-24所示的描述入口自动栏杆行为的UML状态图。

根据说明中的描述,使用表3-11给出的用例名称,给出图3-22中U1、U2和U3所对应的用例。
-
根据说明中的描述,使用表3-11给出的状态名称,给出图3-24中S1~S4所对应的状态。
-
根据你的实体联系图,完成关系模式,并给出训练记录和比赛记录关系模式的主键和外键。
-
如果考虑记录一些特别资深的热心球迷的情况,每个热心球迷可能支持多个球队。热心球迷的基本信息包括:姓名、住址和喜欢的俱乐部等。根据这一要求修改图3-20的实体联系图,给出修改后的关系模式。
-
阅读下列说明,根据要求回答问题1~问题3。
[说明]
某地区举行篮球比赛,需要开发一个比赛信息管理系统来记录比赛的相关信息。
[需求分析结果]
1.登记参赛球队的信息。记录球队的名称、代表地区、成立时间等信息。系统记录球队的每个队员的姓名、年龄、身高、体重等信息。每个球队有一个教练负责管理球队,一个教练仅负责一个球队。系统记录教练的姓名、年龄等信息。
2.安排球队的训练信息。比赛组织者为球队提供了若干个场地,供球队进行适应性训练。系统记录现有的场地信息,包括:场地名称、场地规模、位置等信息。系统可为每个球队安排不同的训练场地,如表3-9所示。系统记录训练场地安排的信息。

3.安排比赛。该赛事聘请有专职裁判,每场比赛只安排一个裁判。系统记录裁判的姓名、年龄、级别等信息。系统按照一定的规则,首先分组,然后根据球队、场地和裁判情况,安排比赛(每场比赛的对阵双方分别称为甲队和乙队)。记录参赛球队、比赛时间、比分、场地名称等信息,如表3-10所示。

4.所有球员、教练和裁判可能出现重名情况。
[概念模型设计]
根据需求阶段收集的信息,设计的实体联系图和关系模式(不完整)如下。
1.实体联系图(图3-20)

2.关系模式
教练(教练编号,姓名,年龄)
队员(队员编号,姓名,年龄,身高,体重, (a)
球队(球队名称,代表地区,成立时间, (b)
场地(场地名称,场地规模,位置)
训练记录( (c) )
裁判(裁判编号,姓名,年龄,级别)
比赛记录( (d) )
根据问题描述,补充4个联系,完善图3-20的实体联系图。
-
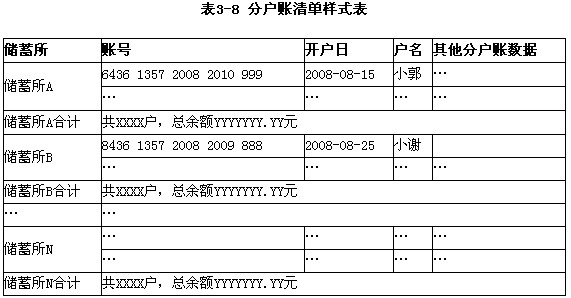
打印分户账清单(表3-8)时,必须以“(4)”作为关键字进行排序才能满足系统需求。 A.储蓄所 B.账号 C.开户日 D.户名 E.其他分户账数据 F.总户数和总余额
-
请使用[说明]中数据字典条目定义形式,将以下(1)和(2)空缺处的内容填写完整。
初录数据=(1) 复录数据=(2)
-
加工1(录入比对处理)除能够检查出初录数据和复录数据不一致之外,还应检测的错误有(3)。 A.显示器无法显示 B.输入的无效字符 C.输入数据的格式 D.输入数据的界限
E.打印机卡纸 F.重复录入同一账户 G.输入的半个汉字 H.汇总数据与会计账目不符
-
请使用[说明]中数据字典条目定义形式,给出图3-18中的“手工分户账”数据流和图3-19中的“初录分户账”和“复录分户账”的关系。
-
阅读以下某建账软件的技术说明和数据流图,根据要求回答问题1~问题6。
[说明]
某商业银行已有一套基于客户机/服务器(C/S)模式的储蓄系统X和一套建账软件Y。建账软件Y主要用于将储蓄所手工处理的原始数据转换为系统X所需的数据格式。该建账软件具有以下功能。
(1)分户账录入:手工办理业务时建立的每个分户账数据均由初录员和复录员分别录入,以确保数据的正确性。
(2)初录/复录比对:将初录员和复录员录入的数据进行一一比较,并标记两套数据是否一致。
(3)数据确认:当上述两套数据完全一致后,将其中任一套作为最终进入系统X的原始数据。
(4)汇总核对和打印:对经过确认的数据进行汇总,并和会计账目中的相关数据进行核对,以确保数据的整体正确性,并打印输出经过确认的数据,为以后核查可能的错误提供依据。该建账软件需要打印的分户账清单样式如表3-8所示。
(5)数据转换:将经过确认的数据转换为储蓄系统X需要的中间格式数据。
(6)数据清除:为加快初录和复录的处理速度,在数据确认之后,可以有选择地清除初录员和复录员录入的数据。
该软件的数据流图如图3-17~图3-19所示,图中部分数据流数据文件的格式如下。
初录分户账=储蓄所号+账号+户名+开户日+开户金额+当前余额+性质
复录分户账=储蓄所号+账号+户名+开户日+开户金额+当前余额+性质
会计账目=储蓄所号+总户数+总余额
操作结果=初录操作结果+比对操作结果+复录操作结果

不考虑数据确认处理(加工2),请指出图3-17~图3-19数据流图中可能存在的错误。
-
请使用[说明]中的词汇,给出数据确认处理所需的数据流,在图3-19建账软件第1层数据流图中的全部可选起点。











