数据结构自考2011年1月真题及答案解析
-
假设用带头结点的单循环链表表示线性表,单链表的类型定义如下:
typedef struct node {
int data;
struct node*next;
}LinkNode,*LinkList;
编写程序,求头指针为head的单循环链表中data域值为正整数的结点个数占结点总数的比例,若为空表输出0,并给出所写算法的时间复杂度。函数原型为:float f34(LinkList head):
-
阅读下列程序。

回答问题:已知整型数组A[ ]={34,26,15,89,42},写出执行函数调用f32(A,5)后的输出结果。
-
已知顺序表的表结构定义如下:
#define MAXLEN 100
typedef int KeyType;
typedef struct {
KeyType key;
InfoType otherinfo;
} NodeType;
typedef NodeType SqList[MAXLEN];
阅读下列程序。
Int f33(SqList R,NodeType X, int p, int q)
{ int m;
if (p>q) return -1;
m=(p+q)/2;
if (R[m].key==X.key) return m;
if (R[m].key>X.key) return f33(R,X,p,m-l);
else return f33(R,X,m+l,q);}
请回答下列问题:
(1)若有序的顺序表R的关键字序列为(2,5,13,26,55,80,105),分别写出X.key=18和X.key=26时,执行函数调用f33(R,X,0,6)的函数返回值。
(2)简述算法f33的功能。
-
假设以二叉链表表示二叉树,其类型定义如下:

回答下列问题:
(1)已知以T为根指针的二叉树如图所示,请写出执行f31(T)的输出结果:
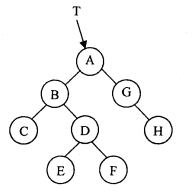
(2)简述算法f31的功能。
-
阅读下列程序。

回答下列问题:
(1)已知矩阵B=,将
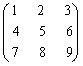 其按行优先存于一维数组A中,给出执行函数调用f30(A,3)后矩阵B的值;
其按行优先存于一维数组A中,给出执行函数调用f30(A,3)后矩阵B的值;(2)简述函数f30的功能。
-
已知待排记录的关键字序列为{25,96,11,63,57,78,44},请回答下列问题:
(1)画出堆排序的初始堆(大根堆);
(2)画出第二次重建堆之后的堆。
-
已知关键字序列为(56,23,41,79,38,62,18),用散列函数H(key)=key%11将其散列到散列表HT[0..10]中,采用线性探测法处理冲突。请回答下列问题:
(1)画出散列存储后的散列表:
(2)求在等概率情况下查找成功的平均查找长度。
-
已知有向图的邻接表如图所示,请回答下面问题:
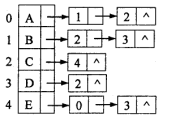
(1)给出该图的邻接矩阵;
(2)从结点A出发,写出该图的深度优先遍历序列。
-
不定长文件指的是文件的____________大小不固定。
-
已知一棵二叉排序树(结点值大小按字母顺序)的前序遍历序列为EBACDFHG,请回答下列问题:
(1)画出此二叉排序树;
(2)若将此二叉排序树看作森林的二叉链表存储,请画出对应的森林。
-
当待排关键字序列基本有序时,快速排序、简单选择排序和直接插入排序三种排序方法中,运行效率最高的是________________。
-
在一棵深度为h的具有n个结点的二叉排序树中,查找任一结点的最多比较次数是______________。
-
一个有n个顶点的无向连通图,最少有________________条边。
-
广义表G=(a,b,(c,d,(e,f)),G)的长度为________________。
-
一棵树T采用孩子兄弟链表存储,如果树T中某个结点为叶子结点,则该结点在二叉链表中所对应的结点一定是________________。
-
设栈S的初始状态为空,若元素a、b、c、d、e、f依次进栈,得到的出栈序列是b、d、c、f、e、a,则栈S的容量至少是________________。
-
长度为零的串称为________________。
-
ISAM文件系统中采用多级索引的目的是( )
- A.提高检索效率
- B.提高存储效率
- C.减少数据的冗余
- D.方便文件的修改
-
在单链表中某结点后插入一个新结点,需要修改_______________个结点指针域的值。
-
数据结构由数据的逻辑结构、存储结构和数据的____________三部分组成。
-
在含有10个关键字的3阶B-树中进行查找,至多访问的结点个数为( )
- A.2
- B.3
- C.4
- D.5
-
某索引顺序表共有元素395个,平均分成5块。若先对索引表采用顺序查找,再对块中元素进行顺序查找,则在等概率情况下,分块查找成功的平均查找长度是( )
- A.43
- B.79
- C.198
- D.200
-
已知关键字序列为(51,22,83,46,75,18,68,30),对其进行快速排序,第一趟划分完成后的关键字序列是( )
- A.(18,22,30,46,51,68,75,83)
- B.(30,18,22,46,51,75,83,68)
- C.(46,30,22,18,51,75,68,83)
- D.(30,22,18,46,51,75,68,83)
-
平均时间复杂度为O(n log n)的稳定排序算法是( )
- A.快速排序
- B.堆排序
- C.归并排序
- D.冒泡排序
-
已知有向图G=(V,E),其中V={V1,V2,V3,V4},E={,,,,},图G的拓扑序列是( )
- A.V1,V2,V3,V4
- B.V1,V3,V2,V4
- C.V1,V3,V4,V2
- D.V1,V2,V4,V3
-
下列叙述中错误的是( )
- A.图的遍历是从给定的源点出发对每一个顶点访问且仅访问一次
- B.图的遍历可以采用深度优先遍历和广度优先遍历
- C.图的广度优先遍历只适用于无向图
- D.图的深度优先遍历是一个递归过程
-
若一棵二叉树中度为1的结点个数是3,度为2的结点个数是4,则该二叉树叶子结点的个数是( )
- A.4
- B.5
- C.7
- D.8
-
设有两个串p和q,其中q是p的子串,则求q在p中首次出现位置的算法称为( )
- A.求子串
- B.串联接
- C.串匹配
- D.求串长
-
对于广义表A,若head(A)等于tail(A),则表A为( )
- A.( )
- B.(( ))
- C.(( ),( ))
- D.(( ),( ),( ))
-
若一棵具有n(n>0)个结点的二叉树的先序序列与后序序列正好相反,则该二叉树一定是( )
- A.结点均无左孩子的二叉树
- B.结点均无右孩子的二叉树
- C.高度为n的二叉树
- D.存在度为2的结点的二叉树
-
已知循环队列的存储空间大小为m,队头指针front指向队头元素,队尾指针rear指向队尾元素的下一个位置,则向队列中插入新元素时,修改指针的操作是( )
- A.rear=(rear-1)%m;
- B.front=(front+1)%m;
- C.front=(front-1)%m;
- D.rear=(rear+1)%m;
-
递归实现或函数调用时,处理参数及返回地址,应采用的数据结构是( )
- A.堆栈
- B.多维数组
- C.队列
- D.线性表
-
下列选项中与数据存储结构无关的术语是( )
- A.顺序表
- B.链表
- C.链队列
- D.栈
-
将两个各有n个元素的有序表归并成一个有序表,最少的比较次数是( )
- A.n-1
- B.n
- C.2n-1
- D.2n




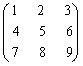 其按行优先存于一维数组A中,给出执行函数调用f30(A,3)后矩阵B的值;
其按行优先存于一维数组A中,给出执行函数调用f30(A,3)后矩阵B的值;