数据结构导论2015年4月真题及答案解析(02142)
-
统计出一棵二叉树中结点数据域的值不小于m的所有结点个数。设二叉树的存储结构为:
typedef struct btnode{
int data;
struct btnode *lchild, *rchile;
}BTNode, *BTree;
-
若采用冒泡排序方法对关键字序列{265,301,751,129,937,863,742,694,076,438}进行升序排序,写出其每趟排序结束后的关键字序列。
-
写出一个将线性表的顺序表存储方式(数组a、表长为n)改成单链表存储方式(其头结点由头指针head指向)的算法。设函数头为:Node * CreateLinkedList(DataType a[], int n)
-
将关键字序列{7,8,30,11,18,9,14}散列存储到一个散列表中,设该散列表的存储空间是一个下标从0开始、大小(HashSize)为10的一维数组,散列函数为H(key)=(key×3)MOD HashSize,处理冲突采用线性探测法。现要求:(1)画出所构造的散列表;(2)计算出等概率情况下查找成功的平均查找长度。
-
带权图(权值非负,表示边连接的两顶点间的距离)的最短路径问题是找出从初始顶点到目标顶点之间的一条最短路径。假定从初始顶点到目标顶点之间存在路径,现有一种解决该问题的方法:①设最短路径初始时仅包含初始顶点,令当前顶点u为初始顶点;②选择离u最近且尚未在最短路径中的一个顶点v,加入到最短路径中,修改当前顶点u=v;③重复步骤②,直到u是目标顶点时为止。现问上述方法能否求得最短路径?若该方法可行,试证明之;否则,举例说明。
-
字符a.b、c、d依次通过一个栈,按出栈的先后次序组成字符串,至多可以组成多少个不同的字符串?并分别写出它们。
-
用冒泡排序算法对n个带有键值的数据元素进行排序,排序结束后所可能历经的最少趟数为______。
-
已知某棵二叉树的先序遍历和中序遍历的结果序列分别为ABCDEFGHI和BCAEDGHFI。试构造出该二叉树,并给出该二叉树的后序遍历结果序列。
-
对如题25图所示的含有3棵树的森林进行先序遍历,得到的结果序列是______。
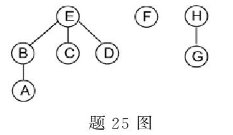
-
插入、选择、冒泡及堆等四种排序方法在各自排序过程中其键值比较的次数与数据元素的初始排列次序无关的有______和堆排序。
-
按关键字的输入序列{30,22,42,7,25}所生成的二叉排序树中,其左子树上的关键字有______。
-
根据图的定义,图中顶点的最少数目是______。
-
高度为3、含有5个结点(编号1~5)的二叉树,其顺序存储结构为
 ,则编号为4的结点的双亲结点的编号为______。
,则编号为4的结点的双亲结点的编号为______。 -
若一棵二叉树中度为1和度为2的结点个数均是3,则该二叉树叶子结点的个数是_____.
-
高度(深度)为h的完全二叉树最少的结点个数是______。
-
在表长为n的顺序表中插入一个数据元素,平均需要移动约______个数据元素。
-
设有二维数组A[8][ 10],按行序优先存储,且每个元素占用2个存储单元,若第一个元素的存储起始位置为b,则存储位置为b+20处的元素为______。
-
栈的特点是先进后出或后进先出,队列的特点是______。
-
根据数据元素之间的关系,通常有四类基本的逻辑结构:集合、线性结构、树形结构、______.
-
数据结构研究的主要内容包括数据的逻辑结构、______、以及对数据及其关系的操作运算。
-
能够使用二分查找算法进行查找的条件是必须以( )
- A.顺序方式存储,且元素按关键字有序
- B.链式方式存储,且元素按关键字有序
- C.顺序方式存储,且元素按关键字无序
- D.链式方式存储,且元素按关键字无序
-
下列排序方法中不稳定的是( )
- A.直接插入排序
- B.堆排序
- C.冒泡排序
- D.二路归并排序
-
对于n个元素的关键字序列{k1,k2….,kn),当且仅当满足关系ki≤k2i且ki≤k2i+1(2i≤n,2i+1≤n)称其为最小堆,反之则为最大堆。以下序列中不符合最小堆或最大堆定义的是( )
- A.{4,10,15,72,39,23,18}
- B.{58,27,36,12,8,23,9}
- C.{4,10,18,72,39,23,15}
- D.{58,36,27,12,8,23,9}
-
下列有关哈夫曼(Huffman)树的描述,不正确的是( )
- A.哈夫曼树的树形唯一,且其WPL值最小
- B.哈夫曼树的树形不一定唯一,但其WPL值最小且相等
- C.哈夫曼字符编码不一定唯一,但总码长最短
- D.哈夫曼树没有严格要求区别左右子树权重次序
-
若某二叉树按后序遍历得到的结果为c、b、a,则可以得到该结果的二叉树有( )
- A.1种
- B.2种
- C.3种
- D.5种
-
对关键字序列{0,2,4,8,16,32,64,128}进行二分查找,则第一个被查找到的关键字是( )
- A.0
- B.8
- C.16
- D.128
-
已知一个图如题10图所示,若从顶点a出发进行广度优先遍历,则可能得到的广度优先搜索( )

- A.acefbd
- B.acbdfe
- C.acbdef
- D.acdbfe
-
若一棵具有n(n>0)个结点的二叉树的先序序列与后序序列正好相反,则该二叉树一定是( )
- A.结点均无左孩子的二叉树
- B.结点均无右孩子的二叉树
- C.存在度为2的结点的二叉树
- D.高度为n的二叉树
-
把特殊矩阵A[10][10]的下三角矩阵压缩存储到一个一维数组M中,则A中元素a[4][3]在M中所对应的下标位置是( )
- A.8
- B.12
- C.13
- D.55
-
在一个单链表中,已知指针q指向指针p所指结点的前驱结点,则删除* p结点的操作语句是( )
- A.q=p;
- B.q=p->next;
- C.q->next=p;
- D.q->next=p->next;
-
对于n(n≥0)个元素构成的线性表L,适合采用链式存储结构的操作是( )
- A.需要频繁修改L中元素的值
- B.需要频繁地对L进行随机查找
- C.需要频繁地对L进行插入和删除操作
- D.要求L存储密度高
-
判断一个带有头结点的链队列为空队列Q的条件是( )
- A.Q.front==NULL
- B.Q.front==Q.rear
- C.Q.front!=Q.rear
- D.Q.rear==NULL
-
为解决计算机与打印机之间速度不匹配的问题,通常设置一个打印数据缓冲区,主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是( )
- A.栈
- B.队列
- C.树
- D.图
-
将长度为n的单链表链接在长度为m的单链表之后的算法时间复杂度为( )
- A.O(n)
- B.O(m)
- C.O(n+m)
- D.O(n×m)
-
设某个算法的计算量是问题规模n的函数:T(n)=anc+blog2n+cn+d,则该算法的时间复度可表示成( )
- A.O(nC)
- B.O(log2n)
- C.O(n)
- D.O(1)

