自考计算机网络数据结构模拟试卷四
-
假设以二叉链表作为二叉树的存储结构,其结点结构为:

照如下给定的函数f34的原型,编写求二叉树中叶子结点所在的最小层次与最大层次的函数。其中,参数 level为函数执行过程中T当前所指结点的层次,其初值为1;lmin与max分别为叶子结点的最小层次与最大层次,它们的初值均为0void f34(BinTree T, int level, int *Imin, int *Imax);
-
二叉排序树的存储结构定义为以下类型
typedef int KeyType;
typedef struct node{
KeyType key;//关键字项
InfoType otherinfo;//其他数据项
struct node Ichild, rchild//左右孩子指针
BSTNode, *BSTree;
阅读算法f33,并回答问题:
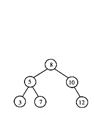
(1)对如题图所示的二叉排序树T,写出33(T,8)返回的指针所指结点的关键字
(2)在哪些情况下算法f33返回空指针?
(3)简述算法f33的功能。
BSTNode f333(BSTree, KeyType)
{BSTNode *p:
if (T==NULL) return NULL:
p=f33(T->lchild, x);
if (p!-NULL) return pi
if (T->key >x) return T:
return f33(T->rchild, x);
}
(1)
(2)
(3)
-
下列程序判断字符串s是否对称,对称则返回1,否则返回0;如f("abba")返回1,f(abab")返回0;在空缺处填写相应的语句。
int f((1))
while (sj]) (2)
for(j-; i
return (3)
}
(1)
(2)
(3)
-
(1)对于下列图G的邻接矩阵,写出函数调用f32(&G,3)的返回值

int f32(MGraph G, int i)
{int d=,j;
for(j=0,j
++) {if(G->edges[]) d++;
if(G->edges[]) d++;
}
return d;
}
(1)
(2)
(3)
(2)简述函数f32的功能。
(3)写出函数f32的时间复杂度
-
算法f31的功能是清空带头结点的链队列Q请在空缺处填入合适的内容,使其成为一个完整的算法。
typedef struct node{
DataType data;
struct node next;
} QueueNode;
typedef struct{
QueueNode *front;//队头指针
QueueNode rear;//队尾指针
}LinkQueue;
void f31(LinkQueue*Q)
{
QueueNode *P,*
P=(1)
while(p! =NULL)
s=p
p=p->next;
free(s):
}
(2) =NULLI
Q->rear=(3)
}
(1)
(2)
(3)
-
试举一个数据结构的例子,叙述其逻辑结构存储结构两方面的内容
-
由字符集{s,t,ae,i}及其在电文中出现的频度构建的哈夫曼树如题27图所示。已知某段电文的哈夫曼编码为1110000100,请根据该哈夫曼树进行译码,写出原来的电文。
-
图G=(V,E),其中:V={0,1,2,3,4,5},E={<0,1>,<0,2>,<1,4>,<2,5>,<5,4><4,3>,<5,3>试写出图G中顶点的所有拓扑排序。
-
对序列(48,37,63,96,22,31,50,55,11进行堆排序,写出构建的初始(大根)堆及前两趟重建堆之后的序列状态。
-
队列只允许在表的一端进行插入,而在另一端进行删除,允许删除的一端称为( )允许插入的一端称为( )
-
下面程序段的时间复杂度是( )i=1;j=0;while (i+j<=n)if (i>j)j++elsei++;
-
一个算法的( )是该算法的时间耗费,它是该算法所求解问题规模n的函数。
-
元素在物理位置上( )相邻20.当三角矩阵的常数为0时,n阶三角矩阵的非零元素个数为
-
在二叉树的第i层上至多有( )个结点(i≥1)
-
顺序栈中,栈空时再做退栈运算将产生溢出,简称( )
-
在用p指针访问单链表时,判断不是访问结束的条件是( )
-
在一棵度为3的树中,度为2的结点个数是1,度为0的结点个数是6,则度为3的结点个数是( )
-
若两个关键字通过散列函数映射到同一个散列地址,这种现象称为( )
-
( )是指抽象数据的组织和与之相关的操作。
-
已知一个长度为19的有序表,按二分查找法对该表进行查找,在表内各元素等概率情况下,查找成功的平均查找长度为【】
- A.68/19
- B.69/19
- C.70/19
- D.71/19
-
下面几个符号串编码集合中,不是前级编码的是【】
- A.{0,10,110,111
- B.{11,10,001,101,0001
- C.{00,010,0110,1000
- D.{0,10,110,111
-
顺序栈s中top为顶指针,指向栈顶元素所在的位置,elem为存放的数组,则元素e进栈操作的主要语句为【】
- A.s. elem[top]-e; s. top-s. top+1;
- B.s. elem[top+1]-e;s. top-s. top+;
- C.s. top-s,top+1;s. elem[top+1]-e;
- D.s. top=s, top+1;s. elem[top]=e;
-
非空带头结点的单循环链表的尾结点p满足【】
- A.p->next==head
- B.p->next==NULL
- C.p==NULL
- D.p==head
-
设树T的度为4,其中度为1、2、3和4的结点个数分别为4、2、1和1,则T中的叶子结点的个数为【】
- A.5
- B.6
- C.7
- D.8
-
与单链表相比,双向链表的优点之一是【】
- A.插入、删除操作更简单
- B.可以进行随机访问
- C.可以省略表头指针或表尾指针
- D.前后访问相邻结点更灵活
-
一个有n个顶点的无向连通图,其边的个数至少为【】
- A.n-1
- B.n
- C.n+1
- D.nlogan
-
广义表A=((a,(b,c),d)的长度为【】
- A.2
- B.3
- C.4
- D.5
-
用普里姆算法和克鲁斯卡尔算法构造的最小生成树,所得到的最小生成树【】
- A.是相同的
- B.是不同的
- C.可能相同,可能不同
- D.无法比较
-
若一组记录的关键字序列为(46,79,56,38,4084),则利用堆排序的方法建立的初始堆(大根堆是【】
- A.84,79,56,38,40,46
- B.79,46,56,38,40,84
- C.84,79,56,46,40,38
- D.84,56,79,40,46,38
-
链栈与顺序栈相比,比较明显的优点是【】
- A.插入操作更加方便
- B.删除操作更加方便
- C.存取操作更加方便
- D.不会出现空间浪费问题
-
已知一棵含50个结点的二叉树中只有一个叶子结点,则该树中度为1的结点个数为【】
- A.0
- B.1
- C.48
- D.49
-
对于一个具有6个顶点和6条边的无向图,若采用邻接表表示,则表头向量的大小为【】
- A.12
- B.5
- C.7
- D.6
-
堆排序的平均执行时间和需附加的存储结点分别是【】
- A.(n2)和O(1)
- B.o(nlog2n)和O(1)
- C.(nlog2n)和O(n)
- D.(n2)和(n)
-
若一棵二叉树具有10个度为2的结点,5个度为1的结点则叶子结点个数为【】
- A.9
- B.11
- C.15
- D.还确定

