数据结构自考2009年10月真题及答案解析
-
假设线性表采用顺序存储结构,其类型定义如下:
#define ListSize 100
typedef struct {
int data[ListSize];
int length;
} SeqList, *Table;
编写算法,将顺序表L中所有值为奇数的元素调整到表的前端。
-
二叉排序树的存储结构定义为以下类型:
typedef int KeyType;
typedef struct node
{KeyType key; /*关键字项*/
InfoType otherinfo; /*其它数据项*/
struct node *1child, *rchild; /*左、右孩子指针*/
} BSTNode, *BSTree;
阅读算法f33,并回答问题:
(1)对如图所示的二叉排序树T,写出f33(T,8)返回的指针所指结点的关键字;
(2)在哪些情况下算法f33返回空指针?
(3)简述算法f33的功能。
BSTNode *f33(BSTree T, KeyType x)
{ BSTNode *p;
if (T= =NULL) return NULL;
p=f33(T->1child, x);
if (p!=NULL)return p;
if (T->key>x)return T;
return f33(T->rchild, x);
}
-
阅读下列算法,并回答问题:
(1)设串s=“OneWorldOneDream”,t="One",pos是一维整型数组,写出算法f32(s,t,pos)执行之后得到的返回值和pos中的值;
(2)简述算法f32的功能。
int strlen(char*s); /*返回串s的长度*/
int index(char*st,char*t);
/*若串t在串st中出现,则返回在串st中首次出现的下标值,否则返回-1*/
int f32(char*s, char*t, int pos[])
{ int i, j, k, ls, lt;
ls=strlen(s);
1t=strlen(t);
if (ls= =0||1t= =0) return-1;
k=0;
i=0;
do {
j=index(s+i, t);
if (j>=0)
{ pos[k++]=i+j;
i+=j+1t;
}
}while(i+1t<=1s j="">=0);
return k;
}
-
阅读下列算法,并回答问题:
(1)无向图G如图所示,写出算法f30(&G)的返回值;
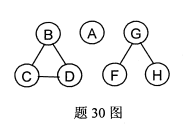
(2)简述算法f30的功能。
#define MaxNum 20
int visited[MaxNum];
void DFS(Graph *g,int i);
/*从顶点vi出发进行深度优先搜索,访问顶点vj时置visited[j]为1*/
int f30(Graph *g)
{ int i,k;
for (i=0; in; i++)/*g->n为图g的顶点数目*/
visited[i]=0;
for (i=k=0; in; i++)
if (visited[i]= =0)
{k++;
DFS(g,i);
}
return k;
}
-
假设学生成绩按学号增序存储在带头结点的单链表中,类型定义如下:
typedef struct Node
{int id; /*学号*/
int score; /*成绩*/
struct Node *next;
} LNode, *LinkList;
阅读算法f31,并回答问题:
(1)设结点结构为
 ,成绩链表A和B如图所示,画出执行算法f31(A,B)后A所指的链表;
,成绩链表A和B如图所示,画出执行算法f31(A,B)后A所指的链表;
(2)简述算法f31的功能。
void f31(LinkList A, LinkList B)
{ LinkList p, q;
p=A->next;
q=B->next;
while (p && q)
{ if (p->idid)
p=p->next;
else if (p->id>q->id)
q=q->next;
else
{ if (p->score<60)
if="" q-="">score<60)
p-="">score=q->score;
else p->score=60;
p=p->next;
q=q->next;
}
}
}
-
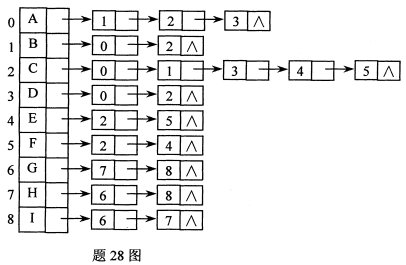
已知无向图G的邻接表如图所示,
(1)画出该无向图;
(2)画出该图的广度优先生成森林。
-
对序列(48,37,63,96,22,31,50,55,11)进行升序的堆排序,写出构建的初始(大根)堆及前两趟重建堆之后的序列状态。
-
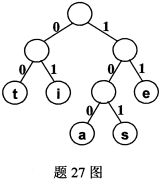
由字符集{s,t,a,e,I}及其在电文中出现的频度构建的哈夫曼树如图所示。已知某段电文的哈夫曼编码为111000010100,请根据该哈夫曼树进行译码,写出原来的电文。
-
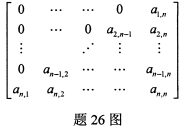
如图所示,在n×n矩阵A中,所有下标值满足关系式i+j
(1)设n=10,元素a4,9存储在sa[p],写出下标p的值;
(2)设元素ai,j存储在sa[k]中,写出由i,j和n计算k的一般公式。
-
常用的索引顺序文件是________文件和________文件。
-
若序列中关键字相同的记录在排序前后的相对次序不变,则称该排序算法是________的。
-
任意一棵完全二叉树中,度为1的结点数最多为________。
-
求最小生成树的克鲁斯卡尔(Kruskal)算法耗用的时间与图中________的数目正相关。
-
在5阶B-树中,每个结点至多含4个关键字,除根结点之外,其他结点至少含________个关键字。
-
广义表L=(a,(b,( )))的深度为________。
-
静态存储分配的顺序串在进行插入、置换和________等操作时可能发生越界。
-
数据的链式存储结构的特点是借助________表示数据元素之间的逻辑关系。
-
如果需要对线性表频繁进行________或________操作,则不宜采用顺序存储结构。
-
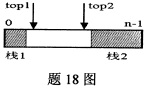
如图所示,可以利用一个向量空间同时实现两个类型相同的栈。其中栈1为空的条件是top1=0,栈2为空的条件是top2=n-1,则“栈满”的判定条件是________。
-
便于进行布尔查询的文件组织方式是( )
- A.顺序文件
- B.索引文件
- C.散列文件
- D.多关键字文件
-
分块查找方法将表分为多块,并要求( )
- A.块内有序
- B.块间有序
- C.各块等长
- D.链式存储
-
对关键字序列(6,1,4,3,7,2,8,5)进行快速排序时,以第1个元素为基准的一次划分的结果为( )
- A.(5,1,4,3,6,2,8,7)
- B.(5,1,4,3,2,6,7,8)
- C.(5,1,4,3,2,6,8,7)
- D.(8,7,6,5,4,3,2,1)
-
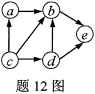
如图所示的有向图的拓扑序列是( )
- A.c,d,b,a,e
- B.c,a,d,b,e
- C.c,d,e,a,b
- D.c,a,b,d,e
-
已知二叉树的中序序列和后序序列均为ABCDEF,则该二叉树的先序序列为( )
- A.FEDCBA
- B.ABCDEF
- C.FDECBA
- D.FBDCEA
-
若非连通无向图G含有21条边,则G的顶点个数至少为( )
- A.7
- B.8
- C.21
- D.22
-
已知森林F={T1,T2,T3,T4,T5},各棵树Ti(i=1,2,3,4,5)中所含结点的个数分别为7,3,5,1,2,则与F对应的二叉树的右子树中的结点个数为( )
- A.2
- B.3
- C.8
- D.11
-
对广义表L= (a,())执行操作tail(L)的结果是( )
- A.()
- B.(())
- C.a
- D.(a)
-
二维数组A[10][6]采用行优先的存储方法,若每个元素占4个存储单元,已知元素A[3][4]的存储地址为1000,则元素A[4][3]的存储地址为( )
- A.1020
- B.1024
- C.1036
- D.1240
-
假设以数组A[n]存放循环队列的元素,其头指针front指向队头元素的前一个位置、尾指针rear指向队尾元素所在的存储位置,则在少用一个元素空间的前提下,队列满的判定条件为( )
- A.rear= =front
- B.(front+1)%n= =rear
- C.rear+1= =front
- D.(rear+1)%n= =front
-
串的操作函数str定义为:
int str(char*s) {
char *p=s;
while (*p!=′\0′)p++;
return p-s;
}
则str(″abcde″)的返回值是( )
- A.3
- B.4
- C.5
- D.6
-
若进栈次序为a,b,c,且进栈和出栈可以穿插进行,则可能出现的含3个元素的出栈序列个数是( )
- A.3
- B.5
- C.6
- D.7
-
对于三个函数f(n)=2008n3+8n2+96000,g(n)=8n3+8n+2008和h(n)=8888nlogn+3n2,下列陈述中不成立的是( )
- A.f(n)是0(g(n))
- B.g(n)是0(f(n))
- C.h(n)是0(nlogn)
- D.

-
指针p、q和r依次指向某循环链表中三个相邻的结点,交换结点*q和结点*r在表中次序的程序段是( )
- A.p->next=r; q->next=r->next; r->next=q;
- B.p->next=r; r->next=q; q->next=r->next;
- C.r->next=q; q->next=r->next; p->next=r;
- D.r->next=q; p->next=r; q->next=r->next;
-
按值可否分解,数据类型通常可分为两类,它们是( )
- A.静态类型和动态类型
- B.原子类型和表类型
- C.原子类型和结构类型
- D.数组类型和指针类型






