试题四(共15分)
阅读以下说明和C函数,填补C函数中的空缺(1)~(5),将解答写在答题纸的对应栏内。
【说明】
函数SetDiff(LA,LB)的功能是将LA与LB中的共有元素从LA中删除,使得LA中仅保留与LB不同的元素,而LB不变,LA和LB为含头结点的单链表的头指针。
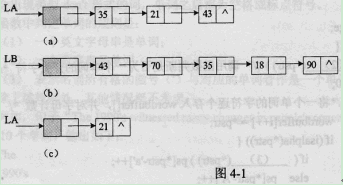
例如,单链表LA、LB的示例如图4-1中的(a)、(b)所示,删除与LB共有的元素后的LA如图4-1中的(c)所示。
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}Node,*LinkList;
函数SetDiff(LinkList LA,LinkList LB)的处理思路如下:
(1)从LA的第一个元素结点开始,令LA的第一个元素为当前元素;
(2)在LB中进行顺序查找,查找与LA的当前元素相同者,方法是:令LA的当前元素先与LB的第一个元素进行比较,若相等,则结束在LB中的查找过程,否则继续与LB的下一个元素比较,重复以上过程,直到LB中的某一个元素与LA的当前元素相等(表明查找成功),或者到达LB的表尾(表明查找失败)为止;
(3)结束在LB表的一次查找后,若在LB申发现了与LA的当前元素相同者,则删除LA的当前元素,否则,保留LA的当前元素;
(4)取LA的下一个元素为当前元素,重复(2)、(3),直到LA的表尾。
【C函数】
void SetDiff(LinkList LA, LinkList LB)
{
LinkList pre,pa,pb;
/*pa用于指向单链表LA的当前元素结点,pre指向pa所指元素的前驱*/
/*pb用于指向单链表LB的元素结点*/
(1) ;/*开始时令pa指向LA的第一个元素*/
pre= LA;
while (pa){
pb= LB->next;
/*在LB中查找与LA的当前元素相同者,直到找到或者到达表尾*/
while( (2) ){
if (pa->data==pb->data)
break;
(3) ;
}
if(!pb){
/*若在LB中没有找到与LA中当前元素相同者,则继续考察LA的后续元素*/
pre =pa;
pa= pa->next;
}
else{
/*若在LB中找到与LA的当前元素相同者,则删除LA的当前元素*/
pre->next= (4);
free(pa);
pa= (5) ;
}
}
}
-
试题六(共15分)
阅读以下说明和Java代码,填补Java代码中的空缺(1)~(6),将解答写在答题纸的对应栏内。
【说明】
己知某公司按周给员工发放工资,其工资系统需记录每名员工的员工号、姓名、工资等信息。其中一些员工是正式的,按年薪分周发放(每年按52周计算);另一些员工是计时工,以小时工资为基准,按每周工作小时数核算发放。
下面是实现该工资系统的Java代码,其中定义了四个类:工资系统类PayRoll,员工类Employee,正式工类Salaried和计时工类Hourly,Salaried和Hourly是Employee的子类。
【Java代码】
abstract class Employee{
protected String name; //员工姓名
protected int empCode; //员工号
protected double salary; //周发放工资
public Employee(int empCode, String name){
this.empCode= empCode;
this.name= name;
}
public double getSalary(){
return this.salary;
}
public abstract void pay();
}
class Salaried (1) Employee{
private double annualSalary;
Salaried(int empCode, String name, double payRate){
super(empCode, name);
this.annualSalary= payRate;
}
public void pay(){
salary= (2) ;//计算正式员工的周发放工资数
System.out.println(this.name+":"+this.salary);
}
}
class Hourly (3) Employee{
private double hourlyPayRate;
private int hours;
Hourly(int empCode, String name, int hours, double payRate){
super(empCode, name);
this.hourlyPayRate= payRate;
this.hows= hours,
}
public void pay(){
salary= (4) ;//计算计时工的周发放工资数
System.out.println(this.name+":"+this.salary);
}
}
public class PayRoll{
private (5) employees[]={
new Salaried(l001,"Zhang San", 58000.00),
//此处省略对其他职工对象的生成
new Hourly(1005,"Li", 12, 50.00)
};
public void pay(Employee e[]){
for (int i=0;i
e[i].pay();
}
}
public static void main(String[] args)
{
PayRoll payRoll= new PayRoll();
payRoll.pay( (6) );
double total= 0.0;
for (int i=0;i
total+=payRoll.employees[i].getSalary();
}
System.out.println(total);
}
}
-
试题四(共15分)
阅读以下说明和C函数,填补C函数中的空缺(1)~(5),将解答写在答题纸的对应栏内。
【说明】
函数SetDiff(LA,LB)的功能是将LA与LB中的共有元素从LA中删除,使得LA中仅保留与LB不同的元素,而LB不变,LA和LB为含头结点的单链表的头指针。
例如,单链表LA、LB的示例如图4-1中的(a)、(b)所示,删除与LB共有的元素后的LA如图4-1中的(c)所示。

链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}Node,*LinkList;
函数SetDiff(LinkList LA,LinkList LB)的处理思路如下:
(1)从LA的第一个元素结点开始,令LA的第一个元素为当前元素;
(2)在LB中进行顺序查找,查找与LA的当前元素相同者,方法是:令LA的当前元素先与LB的第一个元素进行比较,若相等,则结束在LB中的查找过程,否则继续与LB的下一个元素比较,重复以上过程,直到LB中的某一个元素与LA的当前元素相等(表明查找成功),或者到达LB的表尾(表明查找失败)为止;
(3)结束在LB表的一次查找后,若在LB申发现了与LA的当前元素相同者,则删除LA的当前元素,否则,保留LA的当前元素;
(4)取LA的下一个元素为当前元素,重复(2)、(3),直到LA的表尾。
【C函数】
void SetDiff(LinkList LA, LinkList LB)
{
LinkList pre,pa,pb;
/*pa用于指向单链表LA的当前元素结点,pre指向pa所指元素的前驱*/
/*pb用于指向单链表LB的元素结点*/
(1) ;/*开始时令pa指向LA的第一个元素*/
pre= LA;
while (pa){
pb= LB->next;
/*在LB中查找与LA的当前元素相同者,直到找到或者到达表尾*/
while( (2) ){
if (pa->data==pb->data)
break;
(3) ;
}
if(!pb){
/*若在LB中没有找到与LA中当前元素相同者,则继续考察LA的后续元素*/
pre =pa;
pa= pa->next;
}
else{
/*若在LB中找到与LA的当前元素相同者,则删除LA的当前元素*/
pre->next= (4);
free(pa);
pa= (5) ;
}
}
}
-
试题五(共15分)
阅读以下说明和C++代码,填补C++代码中的空缺(1)~(6),将解答写在答题纸的对应栏内。
【说明】
已知某公司按周给员工发放工资,其工资系统需记录每名员工的员工号、姓名、工资等信息。其中一些员工是正式的,按年薪分周发放(每年按52周计算);另一些员工是计时工,以小时工资为基准,按每周工作小时数核算发放。
下面是实现该工资系统的C++代码,其中定义了四个类:工资系统类PayRoll,员工类Employee,正式工类Salaried和计时工类Hourly,Salaried和Hourly是Employee的子类。
【C++代码】
//头文件和域名空间略
const int EMPLOYEE_NUM=5;
class Employee{
protected:
int empCode; ∥员工号
string name; ∥员工姓名
double salary; ∥周发放工资
public:
Employee( const int empCode, const string &name){
this->empCode= empCode; this->name= name;
}
virtual~Employee(){}
virtual void pay()=0;
double getSalary(){ return this->salary; }
};
class Salaried (1){
private: double payRate; //年薪
public:
Salaried(const int empCode,const string &name,double payRate)
:Employee(empCode,name){
this->payRate= payRate;
}
void pay(){
this->salary=(2) ;//计算正式员工的周发放工资数
cout<
name<<":"< salary< }
};
class Hourly (3) {
private:
double payRate; //小时工资数
int hours; //周工作小时数
public:
Hourly(const int empCode, const string &name, int hours, double payRate)
:Employee(empCode,name){
this->payRate= payRate; this->hours= hours,
}
void pay(){
this->salary= (4) ;//计算计时工的周发放工资数
cout<
name<<":"< salary< }
};
class PayRoll{
public:
void pay(Employee* e[]){
for (int i=0;i
e[i]->pay();
}
}
};
int main(){
PayRoll* payRoll= new PayRoll;
(5)employees[EMPLOYEE_ NUM]={
new Salaried(l00l,"Zhang San", 58000.00),
//此处省略对其他职工对象的生成
new Hourly(1005,"L1", 12, 50.00),
};
payRoll->pay ( (6) );
double total= 0.0;
for (int i=0;i< EMPLOYEE_NUM; i++)
{ total+=employees[il->getSalary(); } //统计周发放工资总额
cout<<"总发放额="<
delete payRoll; retum 0;
}
-
试题二(共15分)
阅读以下说明、C程序代码和问题1至问题3,将解答写在答题纸的对应栏内。
【说明1】
设在某C系统中为每个字符型数据分配1个字节,为每个整型(int)数据分配4个字节,为每个指针分配4个字节,sizeof(x)用于计算为x分配的字节数。
【C代码】
#include
#include
int main()
{ int arr[5]={10,20,30};
char mystr[]="JustAtest\n";
char *ptr= mystr;
printf("%d%d%d\n", sizeof(int),sizeof(unsigned int),sizeof(arr));
printf("%d%d\n",sizeof(char),sizeof(mystr));
printf("%d%d%d\n",sizeof(ptr),sizeof(*ptr),strlen(ptr));
return 0;
}
【问题1】(8分)
请写出以上C代码的运行结果。
【说明2】
const是C语言的一个关键字,可以用来定义“只读”型变量。
【问题2】(4分)
(1)请定义一个“只读”型的整型常量size,并将其值初始化为10;
(2)请定义一个指向整型变量a的指针ptr,使得ptr的值不能修改,而ptr所指向的目标变量的值可以修改(即可以通过ptr间接修改整型变量a的值)。
注:无需给出整型变量a的定义。
【问题3】(3分)
某C程序文件中定义的函数f如下所示,请简要说明其中static的作用,以及形参表“const int arr[]”中const的作用。
static int f(const int arr[])
{
/*函数体内的语句省略*/
}
-
试题三(共15分)
阅读以下说明和C函数,填补C函数中的空缺(1)~(6),将解答写在答题纸的对应栏内。
【说明】
函数numberOfwords (char message[])的功能是计算存储在message字符数组中的一段英文语句中的单词数目,输出每个单词(单词长度超过20时仅输出其前20个字母),并计算每个英文字母出现的次数(即频数),字母计数时不区分大小写。
假设英文语句中的单词合乎规范(此处不考虑单词的正确性),单词不缩写或省略,即不会出现类似don't形式的词,单词之后都为空格或标点符号。
函数中判定单词的规则是:
(1)一个英文字母串是单词;
(2) 一个数字串是单词;
(3)表示名词所有格的撇号(')与对应的单词看作是一个单词。
除上述规则外,其他情况概不考虑。
例如,句子“The 1990's witnessed many changes in people's concepts ofconservation”中有10个单词,输出如下:
The
1990's
witnessed
many
changes
in
people's
concepts
of
conservation
函数numberOfijvords中用到的部分标淮库函数如下所述。

【C函数】
int numberOfwords (char message[])
{
char wordbuffer[21],i=0; /*i用作wordbuffer的下标*/
(1) pstr;
int ps[26]={0); /*ps[0]用于表示字母'A'或'a'的频数*/
/*ps[1]用于表示字母'B'或'b'的频数,依此类推*/
int wordcounter=0;
pstr=message;
while (*pstr){
if((2)(*pstr)){/*调用函数判断是否为一个单词的开头字符*/
i=0;
do{/*将一个单词的字符逐个存入wordbuffer[],并对字母计数*/
wordbuffer[i++]=*pstr;
if(isalpha(*pstr)){
if (3) (*pstr))ps[*pstr-'a']++;
else ps[*pstr-'A']++;
}
(4) ; /*pstr指向下一字符*/
}while (i<20&&(isalnum(*pstr)||*pstr=='\"));
if (i>=20) /*处理超长单词(含名词所有格形式)*/
while (isalnum(*pstr)||*pstr=='\"){pstr++;}
(5) ='\0';/*设置暂存在wordbuffepstrr中的单词结尾*/
wordcounter++; /*单词计数*/
puts(wordbuffer); /*输出单词*/
}
(6); /*pstr指向下一字符*/
}
retum wordcounter;
}
-
试题一(共15分)
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的对应栏内。
【说明】
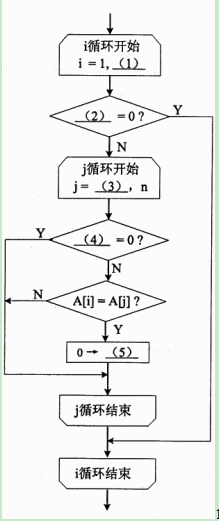
已知数组A[1:n]中各个元素的值都是非零整数,其中有些元素的值是相同的(重复)。为删除其中重复的值,可先通过以下流程图找出所有的重复值,并对所有重复值赋0标记之。该流程图采用了双重循环。
处理思路:如果数组A某个元素的值在前面曾出现过,则该元素赋标记值0。例如,假设数组A的各元素之值依次为2,5,5,1,2,5,3,则经过该流程图处理后,各元素之值依次为2,5,0,1,0,0,3。
【流程图】


高级经济师考试试题精选练习(1)
高级经济师考试模拟练习题之单选题(1
高级经济师考试试题精选练习(2)
高级经济师考试试题精选练习(3)
高级经济师考试试题:经济法案例试题精
高级经济师考试模拟试题及答案
高级经济师考试试题及答案:单选练习题
高级经济师考试试题:经济法案例试题精
高级经济师考试模拟题及答案练习(1)
高级经济师考试模拟题及答案练习(2)